- Published on
배포한 사이트가 검색이 안돼요 !!
- Authors

- Name
- Yeon Kyung Nae
검색이 안 돼요!
실무에서 겪은 robots.txt 설정 실수와 SEO 복구 과정
웹 서비스를 운영하다 보면 아주 사소한 설정 하나가 검색 노출 전체를 막아버리는 큰 문제로 이어질 수 있습니다.
이번 글에서는 제가 실무에서 직접 겪은 robots.txt 설정 실수로 인한 검색 미노출 이슈와, 이를 분석하고 해결한 경험을 공유합니다.
1. 문제 발생
서비스 런칭 이후, 내부 검색 테스트 중 네이버에 서비스명이 검색되지 않는 현상을 발견했습니다.
검색 결과에는 "robots.txt가 읽을 수 없는 사이트" 라는 문구가 함께 표시되어 있었고,
서비스명이 아닌 엉뚱한 회사 이름이 노출되는 문제가 있었습니다.
2. 원인 분석
배포 중 다음과 같은 설정이 robots.txt에 잘못 포함되어 있었던 것이 원인이었습니다:
User-agent: *
Disallow: /
이 설정은 모든 검색 엔진에게 "사이트 전체를 크롤링하지 마세요"라고 지시하는 것으로,
결과적으로 검색 엔진이 페이지를 인덱싱하지 못하게 됩니다.
테스트 환경용 설정이 실수로 운영 환경에 적용된 상태였고, 해당 코드가 배포된 이후부터 검색 노출이 차단되었습니다.
3. 대응 및 복구
✅ robots.txt 수정
Disallow: /삭제 또는 주석 처리- 필요에 따라 일부 관리자 페이지만 차단하도록 수정
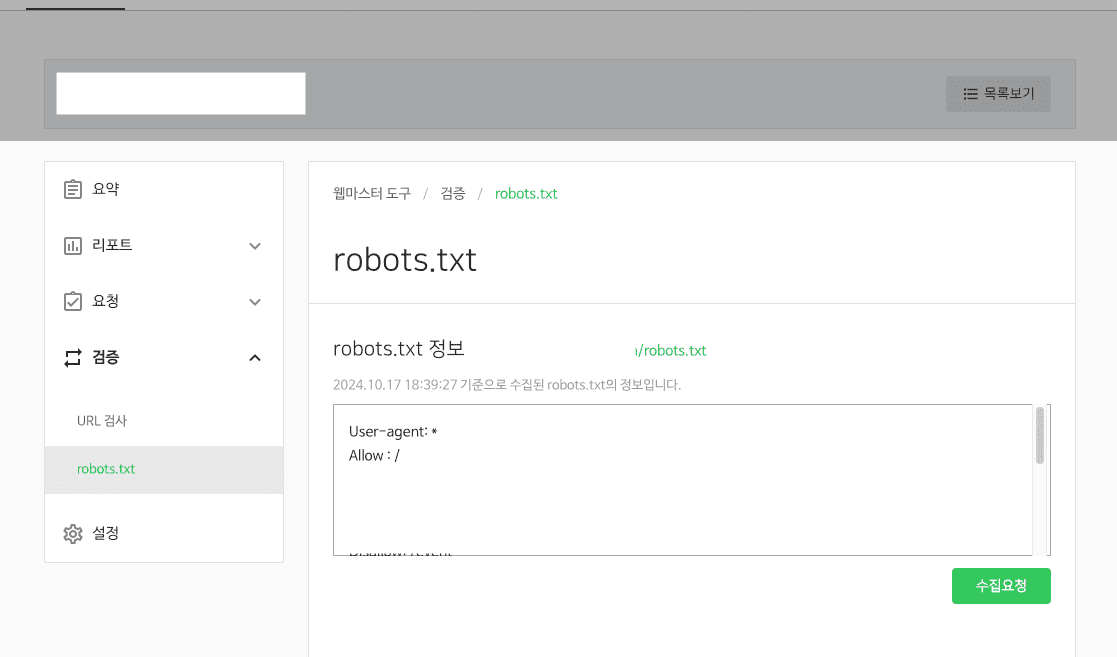
✅ 네이버 웹마스터도구 등록 및 수집 요청
- 메타태그를 활용한 도메인 인증
- robots.txt와 sitemap.xml 등록
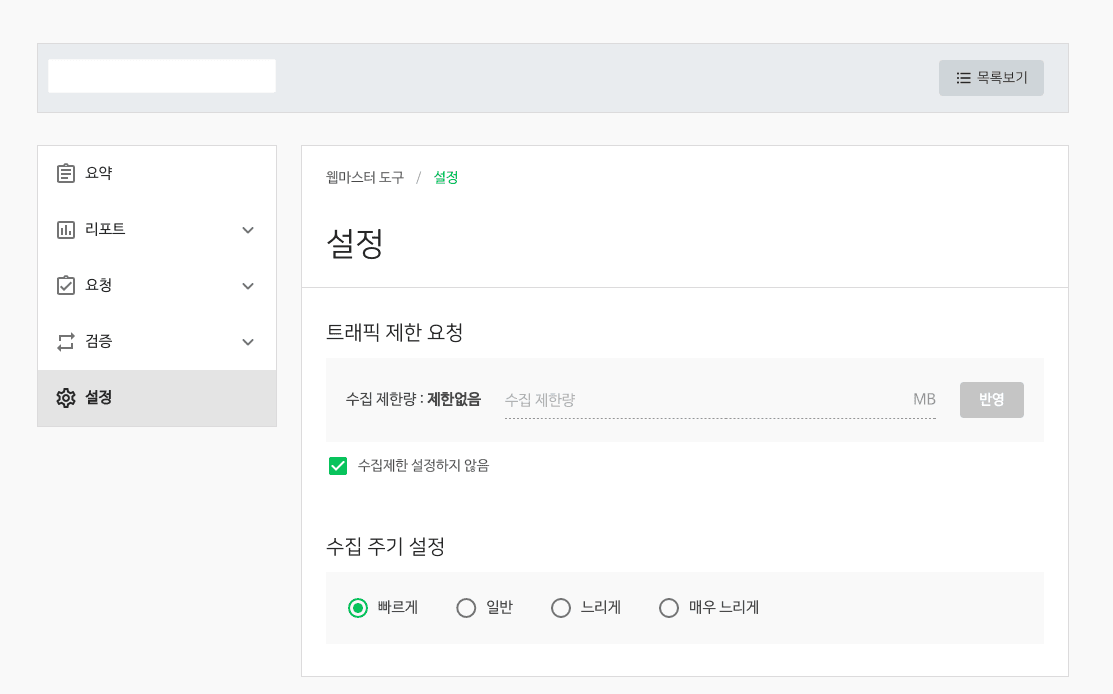
- 수집 주기를 빠르게 설정하여 색인 요청
⏱ 처리 시간
- 문제 확인: 10월 17일 14:17
- 검색 정상화 확인: 10월 17일 20:35 (약 6시간 소요)
4. 회고
robots.txt 하나로 서비스의 검색 접근성이 완전히 차단될 수 있다는 것을 체감했습니다.
SEO는 마케팅의 영역으로만 생각하기 쉽지만, 프론트엔드 개발자가 책임져야 할 중요한 기술 영역입니다.
특히 Next.js, SSR/SSG 구조를 사용하는 프로젝트에서는 검색 최적화를 고려한 구조 설계가 매우 중요합니다.
결론
이번 경험을 통해 SEO 설정의 중요성을 다시 한 번 체감했고, 기술적인 실수가 브랜드 신뢰도에 영향을 줄 수 있다는 점을 몸소 배웠습니다.